March 2020: I was planning to write about CPU microarchitecture analysis for a long time. I started writing this post more than a year ago, just before the beginning of COVID-19. But with so many things happening around (and new parenting responsibilities 👧), this got delayed for quite a long time. Finally getting some weekend time to get this out!
Like previous blog posts, this also became longer and longer as I started writing details. But I believe this gives a comprehensive overview of LIKWID capabilities with the examples and can be used as a step-by-step guide. The section about hardware performance counters is still very shallow and I hope to write a second part in the future. I have added Table of Contents so that you can jump to the desired section based on your experience/expectation.
Table of Contents
- I. Introduction
Start here to understand motivation and background about the LIKWID. - II. Brief Overview of CPU Architecture
Start here to get an idea of modern CPU architecture and common terminologies. - III. What do we want to understand using LIKWID?
Start here to know what we are going to achieve in this blog post. - IV. Installing LIKWID
Start here to begin with LIKWID installation and common issues. - V. LIKWID In Practice
Start here to understand how LIKWID can be used for various use cases.- 1. Understanding topology of a compute node : #threads, #cores, #sockets, #caches, #memories
- 2. Understanding topology of a multi-socket node with GPUs
- 3. Thread affinity domains in LIKWID
- 4. How to pin threads to hyperthreads, cores, sockets or NUMA domains?
- 5. likwid-bench : Microbenchmarking framework
- 6. Understanding workgroups in the likwid-bench
- 7. Understand structure and output of likwid-bench
- 8. What is peak FLOPS performance of a CPU?
- 9. Do we get better FLOPS with Hyper-Threading?
- 10. What is memory bandwidth of a CPU? What role vectorisation play in bandwidth?
- 11. How many cores are required to saturate bandwidth?
- 12. Measuring impact from caches
- 13. What is NUMA effect? How to quantify the impact?
- 14. Changing CPU frequency and turbo mode
- 15. How to measure power consumption?
- 16. Measuring performance counters with ease!
- 17. But, after all this, how can I analyse my own application?
- VI. Additional Resources
See additional references that can be helpful to explore this further. - VII. Credit
Praise the fantastic developer team!
I. Introduction
Modern processors are complex with more cores, different levels of parallelism, deeper memory hierarchies, larger instruction sets, and a number of specialized units. As a consequence, it is increasingly becoming difficult to predict, measure, and optimize application performance on today's processors. With the deployment of larger (and expensive) computing systems, optimizing applications to exploit maximum CPU performance is an important task. Even though application developers are taking care of various aspects like locality, parallelization, synchronization, vectorization, etc., making optimal use of processors remains one of the key challenges. For low-level performance analysis, there are few vendor-specific tools available but if you are looking for a lightweight, easy-to-use tool for different CPU platforms then LIKWID must be on yout list!
LIKWID (Like I Knew What I am Doing) is a toolsuite developed at Erlangen Regional Computing Center (RRZE) over last ten years. It provides command-line utilities that help to understand thread and cache topology of a compute node, enforce thread-core affinity, manipulate CPU/Uncore frequencies, measure energy consumption and compute different metrics based on hardware performance counters. LIKWID also includes various microbenchmarks that help to determine the upper bounds of a processor performance. It supports Intel, AMD, ARM, and IBM POWER CPUs. The last release (v5) of LIKWID has added very basic support for NVIDIA GPUs. If you want to understand more about LIKWID and its architecture, this 2010 paper gives a good overview. Also, see resource section for other useful references.
I became familiar with LIKWID in 2014 when one of a master student from the LIKWID group started an internship in our group for performance modeling work. For large-scale performance analysis I often use a bunch of other profiling tools (see my list here) but LIKWID always comes in handy when need to look into microarchitecture details and tune single node performance.
Do You Want To Understand Your CPU Better? Then let's get started!
II. Brief Overview of CPU Architecture
With diverse architecture platforms, it is difficult to summarise modern CPU architectures in a blog post. And, it's not the goal of this post anyway! There are already excellent resources available. But, for the discussion here we would like to have a high-level understanding and common terminology in place. So, before jumping into the LIKWID, we will look at the high-level organization of compute node and processor architecture. Note that from one computing system to another and one CPU family to another, the organization and architecture details will be different. But the goal here is to highlight certain aspects that give an idea of what one should be aware of.
Compute Node Architecture
A compute node can be considered a basic building block of computing systems today. A node consists of one or more sockets. A socket is hardware on the motherboard where processor (CPU) is mounted. A processor has components like ALU, FPU, Registers, Control Unit, and Caches are collectively called a core of a processor. These components can be replicated on a single chip to form a multi-core processor. Each core can execute one or more threads simultaneously using hyper-threading technology. Each core has one or more levels of private caches local to the core. There is often a last-level cache that is shared by all cores on a processor. Each socket has main memory which is accessible to all processors in a node through some form of inter-socket link (see HT, QPI or UPI). If the processor can access its own socket memory faster than the remote socket then the design is referred to as Non-Uniform Memory Access (NUMA). A generalized sketch of a typical compute node is shown in the below figure. The number of sockets, cores, threads, and cache levels are chosen for simplicity.
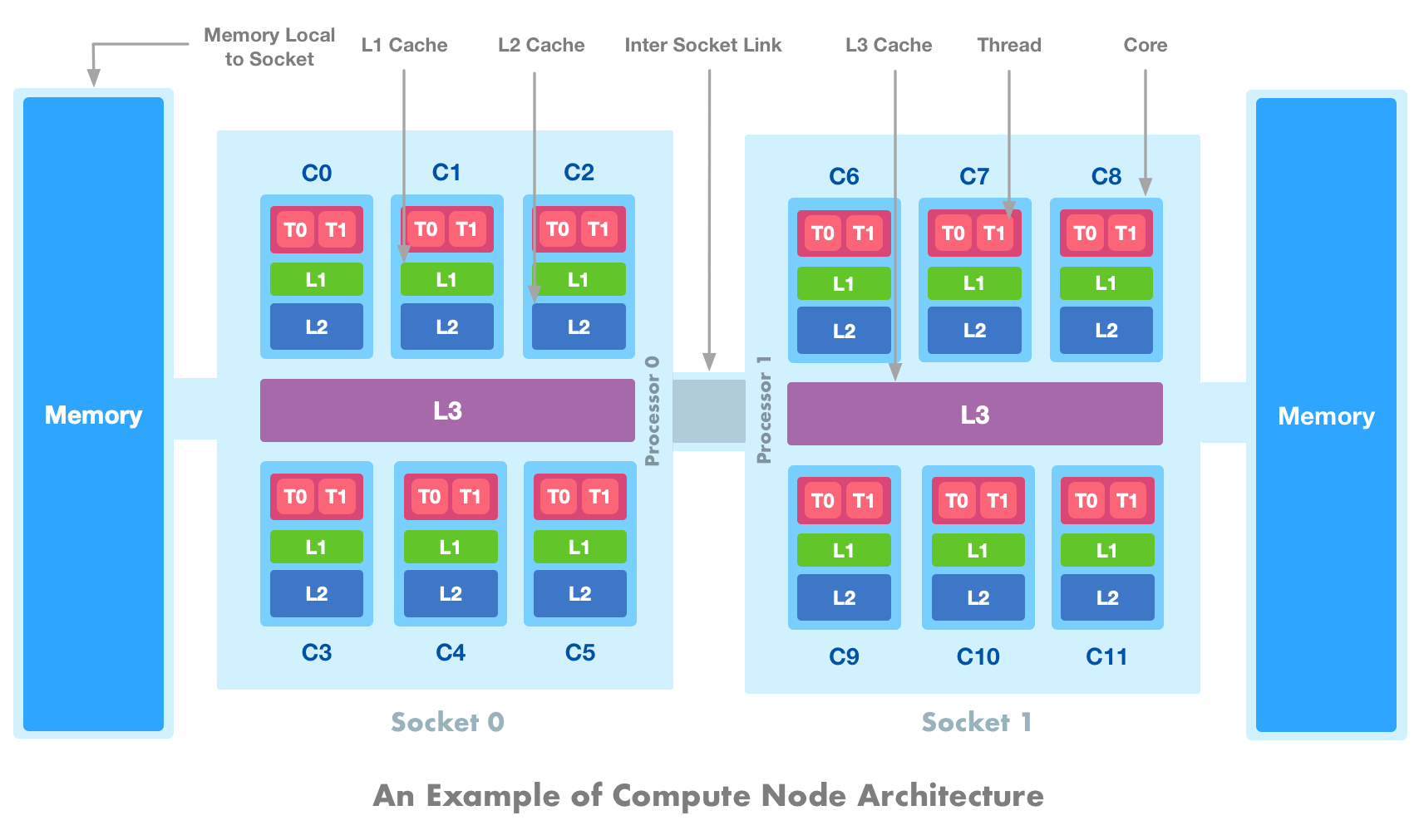
In the above figure, we have depicted a dual-socket system (Socket 0 and Socket 1) where each socket contains a 6-core processor (C0-C5 and C6-C11). Each core is 2-way SMT i.e. can execute two threads simultaneously (T0-T1). There are two levels of caches (L1 and L2) local to each core. There is also an L3 cache that is shared across all 6 cores on a single processor. Two sockets are connected by an inter-socket bus through which the entire memory is accessible. There are two NUMA domains and access to local memory on each socket is faster than accessing memory on a remote socket via inter socket link. Note that the cores and memories on a socket can be further subdivided into multiple sub-domains for improved core-to-memory access (e.g. using SubNUMA Clustering (SNC) on modern Intel CPUs).
CPU Core Architecture
Once we understand compute node architecture, the next step is to understand the microarchitecture of the individual processor and this is where the complexity comes in. A node architecture presented in the previous figure is quite generic across the systems. But, processor microarchitectures are quite diverse from one vendor to another or even from one processor generation to another. In this blog post, we are not going to look into performance bottlenecks within the CPU core and I plan to write a second part to cover this topic. But to get an idea of the individual processor and its functioning, let's take a look at the Intel Skylake processor core. Based on the Intel Press Workshop 2017 presentation, a simplified schematic representation of the core is shown below:
{kind=link}
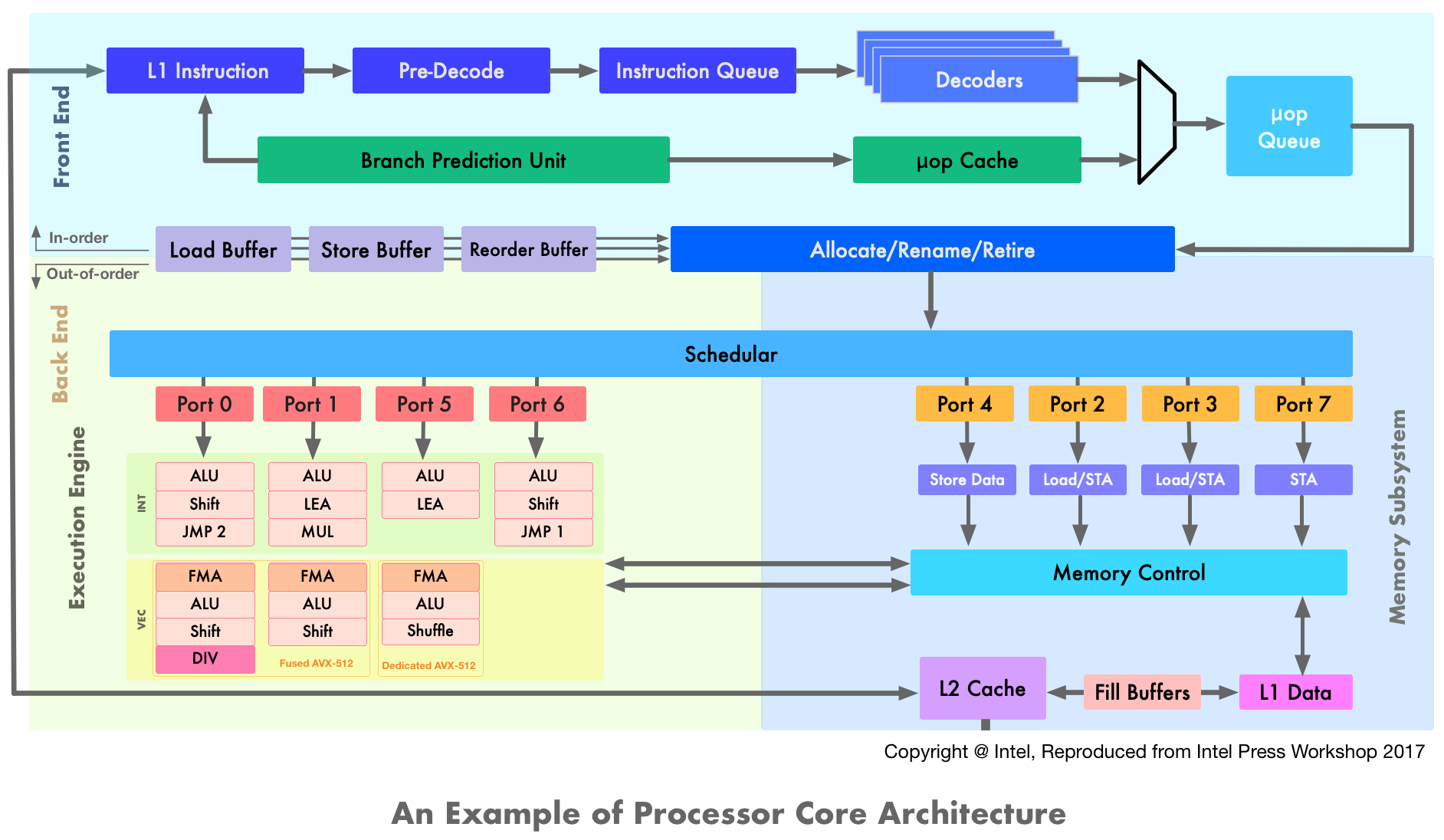
As highlighted in the three different color blocks, the processor core can be divided into three main parts: Front-End, Execution Engine (Back-End), and Memory Subsystem. Here is a brief overview of these building blocks:
-
Front-End: An in-order issue front-end is responsible for fetching instructions from memory to instruction cache, decoding them, and delivering them to the Execution Engine. The instructions can be complex, variable in length, and may contain multiple operations. At the Pre-Decode buffer, the instructions boundaries get detected and then stored into Instruction Queue. Decoders pick the instructions and convert them into regular, fixed-length µOPs. As decoding complex instructions is an expensive task, the results are stored in µOP cache. The Allocate/Rename block reorders the µOPs to dataflow order so that they can be executed as their sources are ready and execution resources are available. The Retire unit ensures that the executed µOPs are visible according to the original program order. The scheduler store the µOPs which are waiting for execution and can dispatch a maximum of 8 µOPs per cycle (i.e. one per port).
-
Execution Engine: An out-of-order, superscalar Execution Engine is responsible for the execution of µOPs sent by the scheduler. It consists of multiple Execution Units each dedicated to certain types of µOPs. Some Execution Units are duplicated to allow simultaneous execution of certain µOPs in parallel. The Execution Engine has support for Intel's AVX-512 instruction set which can perform 8 double or 16 single-precision operations per instruction. Note that AVX-512 fuses Port 0 and Port 1 (which are 256-bit wide) to form a 512-bit FMA unit. In the high-end Xeons, there is a second dedicated 512-bit wide AVX-512 FMA unit on Port 5. The Execution Engine also has connections to and from the caches.
-
Memory Subsystem: The Memory Subsystem is responsible for memory load and store requests and their ordering. The µOPs related to data transfer are dispatched to Memory Subsystem by the Schedular via dedicated ports. Each core has a separate L1 cache for data and instruction whereas the L2 cache is shared for data as well as for instructions. Fill Buffer (FB) keeps track of outstanding cache misses and stores the data before loading into the L1 cache. The memory control unit manages the flow of data going to and from the execution units. On Skylake the memory subsystem can sustain two memory reads (Port 2 and Port 3) and one memory write (Port 4) per cycle. Port 7 handles the memory address calculation required for fetching data from the memory.
There are many other details involved in each part and it's out of the scope of this blog post to cover them in detail. If you want to dive into details, you can take a look at Intel 64 and IA-32 Architectures Optimization Reference Manual and wikichip.org.
III. What do we want to understand using LIKWID?
As application developers or performance engineers, we have heard a number of guidelines and recommendations in one or another form. For example, caches are faster, hyperthreading doesn't always help, memory bandwidth can be saturated by smaller core count, access to memory on remote NUMA node is slower etc etc. But, if doing X is slower than Y then the question is how much slower? The obvious answer "it depends" doesn't help that much. LIKWID doesn't provide direct answers to all these questions but provides a good framework to quantify the impact in a systematic way. In this blog post, using LIKWID, we are going to:
- Understand compute node topology including cores, caches, memories and GPUs
- Understanding how to pin threads to virtual cores, physical cores or sockets
- Measure performance of a core and a compute node
- Measure bandwidth using a core and a compute node
- Understand the effect of memory locality on performance
- Understand the effect of clock speed on performance
- Understand the effect of hyper-threading
- Measure energy consumption
- Measure hardware performance counters for flops, memory accesses
- Understand how CPU frequency can be changed along with turbo mode
- Understand how to analyze our own application
IV. Installing LIKWID
Secutiry Considerations In order to enable hardware performance counter analysis, access to model-specific registers (MSR) is required on the x86 platform. These MSR registers can be accessed via special instructions which can be only executed in protected mode or via device files on newer kernels (>= v2.6). By default, the root user has permissions to access these registers. One can install LIKWID with the root user but one has to consider security aspects especially on shared computing systems. An alternative approach is a solution based on access daemon, see this section in the official documentation. If you don't have root permissions on the system then you can use perf_event backend but that could be with limited features. See this documentation. For the sake of simplicity and easy setup we are installing with a root user here.
Installing LIKWID is easy on any Linux distribution. Apart from basic dependencies (like make, perl, zlib) other dependencies are shipped with the released tarballs. We can download and build LIKWID as:
Manual Installation
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
wget http://ftp.fau.de/pub/likwid/likwid-5.1.0.tar.gz tar -xzf likwid-5.1.0.tar.gz cd likwid-5.1.0 # change install prefix and build sed -i -e "s#^PREFIX .*#PREFIX ?= $HOME/install#g" config.mk # a quick bug fix for 5.1.0, see #386 on GitHub sed -i '145s/1E6/1E3/' likwid-setFrequencies # ONLY IF you have NVIDIA GPU system, make sure $CUDA_HOME is set to CUDA installation sed -i -e "s#^NVIDIA_INTERFACE .*#NVIDIA_INTERFACE = true#g" config.mk make -j |
And now if we try to install as a normal user then we should get the following error:
|
1 2 3 4 5 6 |
make install ===> INSTALL access daemon to /home/kumbhar/install/sbin/likwid-accessD install: cannot change ownership of '/home/kumbhar/install/sbin/likwid-accessD': Operation not permitted make: *** [install_daemon] Error 1 |
This is because LIKWID is trying to change ownership of likwid-accessD daemon to get elevated permissions. As a normal user this it's not possible to change ownership to root. An easy way to avoid this error is to perform the install step using the root or sudo command:
|
1 2 3 |
sudo make install |
Again, prefer this approach only after going through the security considerations (discussed here).
Lets now add the installation directory to PATH:
|
1 2 3 |
export PATH=$HOME/install/bin:$PATH |
Spack Based Installation
If you are using Spack for building scientific software then you can install LIKWID as:
|
1 2 3 4 5 6 |
spack install likwid # load spack in PATH spack load likwid |
Note that as of today, Spack installs LIKWID with perf_event backend. So you have to make sure to update to the appropriate level in /proc/sys/kernel/perf_event_paranoid (see this documentation on kernel.org). If you have set up a separate Linux group for a set of users to use LIKWID with extra permissions then you have to set LIWKID_GROUP environmental variable and use setgid variant as:
|
1 2 3 4 5 6 7 |
export LIWKID_GROUP=linux-group-name spack install likwid+setgid # load spack in PATH spack load likwid |
Current Spack recipes set BUILDFREQ=false and BUILDDAEMON=false which means likwid-setFrequencies and access daemon likwid-accessD are not built. See the discussion in google group and GitHub issue.
Either with manual installation or Spack-based installation, we hope everything is installed correctly. Let's do a basic check:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
$ likwid-topology -------------------------------------------------------------------------------- CPU name: Intel(R) Core(TM) i7-5960X CPU @ 3.00GHz CPU type: Intel Xeon Haswell EN/EP/EX processor ... $ likwid-perfctr -i -------------------------------------------------------------------------------- CPU name: Intel(R) Core(TM) i7-5960X CPU @ 3.00GHz CPU type: Intel Xeon Haswell EN/EP/EX processor CPU clock: 3.00 GHz CPU family: 6 ... $ likwid-perfctr -e -------------------------------------------------------------------------------- This architecture has 42 counters. Counter tags(name, type<, options>): BBOX0C0, Home Agent box 0, EDGEDETECT|THRESHOLD|INVERT BBOX0C1, Home Agent box 0, EDGEDETECT|THRESHOLD|INVERT ... |
Looks great! Both commands are finishing without any error. If you see any errors with the above commands then refer to the summary I posted in this GitHub issue. Here are some additional notes:
- To see various build options, take a look at
config.mk. Commonly used options inconfig.mkare:COMPILER,PREFIX,ACCESSMODE,NVIDIA_INTERFACE,BUILDDAEMON,BUILDFREQ. - LIKWID can be built on top of
perf_eventbackend instead of native access. See details here. - Instrumentation under
likwid-benchcan be enabled with an optionINSTRUMENT_BENCH = true. - If you are using LIKWID in a cluster and LIKWID is preinstalled then some advanced features might have been disabled (e.g. changing clock frequencies).
V. LIKWID In Practice
Instead of writing about each tool (which is already available via GitHub Wiki), we will try to address specific questions discussed in the Section 3 using different tools provided by LIKWID. Throughout this post, we are going to use a compute node with two Cascade Lake 6248 CPUs @ 2.5 GHz (20 physical cores each and hyperthreading enabled). For the next one section about node topology we will also use linux desktop with a Haswell 4790 CPU @ 3.0 GHz (4 physical cores and hyperthreading enabled).
1. Understanding topology of a compute node : #threads, #cores, #sockets, #caches, #memories
Before diving into performance analysis, first thing is to get a good understanding of the compute node itself. You might have used tools like numactl, hwloc-ls, lscpu or simply cat /proc/cpuinfo to understand the CPU and cache organization. But based on the platform and BIOS settings, information like CPU numbers could be different on the same compute hardware. LIKWID tries to avoid such discrepancies by using information from different sources like hwloc library, procfs/sysfs, cpuid instruction etc. and provides a uniform view via tool called likwid-topology. It shows the topology of threads, caches, memories, GPUs in a textual format.
Let's start with a Linux desktop with a Haswell CPU. Using lscpu command we can find out various properties as:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$ lscpu | grep -E '^Thread|^Core|^Socket|^CPU|^NUMA|cache:' CPU(s): 8 Thread(s) per core: 2 Core(s) per socket: 4 Socket(s): 1 NUMA node(s): 1 L1d cache: 128 KiB L1i cache: 128 KiB L2 cache: 1 MiB L3 cache: 8 MiB NUMA node0 CPU(s): 0-7 |
This is a single socket, quad-core CPU with hyperthreading enabled (i.e. 8 virtual cores). As there is a single socket and no SNC is enabled, there is only one NUMA domain. If we want to find out how threads and caches are organized then we can do:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ lscpu --all --extended CPU NODE SOCKET CORE L1d:L1i:L2:L3 ONLINE MAXMHZ MINMHZ 0 0 0 0 0:0:0:0 yes 4000.0000 800.0000 1 0 0 1 1:1:1:0 yes 4000.0000 800.0000 2 0 0 2 2:2:2:0 yes 4000.0000 800.0000 3 0 0 3 3:3:3:0 yes 4000.0000 800.0000 4 0 0 0 0:0:0:0 yes 4000.0000 800.0000 5 0 0 1 1:1:1:0 yes 4000.0000 800.0000 6 0 0 2 2:2:2:0 yes 4000.0000 800.0000 7 0 0 3 3:3:3:0 yes 4000.0000 800.0000 |
Here we can see CPU 0 and CPU 4 are mapped to same physical core Core 0. They share all data instruction caches (0:0:0:0 represent L1d:L1i:L2:L3 which is 0th L1 data cache, L1 instruction cache, L2 data cache and L3 data cache). Maximum and minimum CPU freqency along with CPU status (online or offline) is shown as well.
Using likwid-topology we can get the similar information in a more intuitive way. For example, here is the output of likwid-topology command on the same node:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
$ likwid-topology -g -------------------------------------------------------------------------------- CPU name: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz CPU type: Intel Core Haswell processor (1) CPU stepping: 3 ******************************************************************************** Hardware Thread Topology ******************************************************************************** Sockets: 1 Cores per socket: 4 (2) Threads per core: 2 -------------------------------------------------------------------------------- HWThread Thread Core Socket Available 0 0 0 0 * 1 0 1 0 * 2 0 2 0 * 3 0 3 0 * (3) 4 1 0 0 * 5 1 1 0 * 6 1 2 0 * 7 1 3 0 * -------------------------------------------------------------------------------- Socket 0: ( 0 4 1 5 2 6 3 7 ) (4) -------------------------------------------------------------------------------- ******************************************************************************** Cache Topology ******************************************************************************** Level: 1 Size: 32 kB Cache groups: ( 0 4 ) ( 1 5 ) ( 2 6 ) ( 3 7 ) -------------------------------------------------------------------------------- Level: 2 Size: 256 kB (5) Cache groups: ( 0 4 ) ( 1 5 ) ( 2 6 ) ( 3 7 ) -------------------------------------------------------------------------------- Level: 3 Size: 8 MB Cache groups: ( 0 4 1 5 2 6 3 7 ) -------------------------------------------------------------------------------- ******************************************************************************** NUMA Topology ******************************************************************************** NUMA domains: 1 -------------------------------------------------------------------------------- Domain: 0 Processors: ( 0 4 1 5 2 6 3 7 ) Distances: 10 (6) Free memory: 3027.21 MB Total memory: 15955 MB -------------------------------------------------------------------------------- ******************************************************************************** Graphical Topology (7) ******************************************************************************** Socket 0: +---------------------------------------------+ | +--------+ +--------+ +--------+ +--------+ | | | 0 4 | | 1 5 | | 2 6 | | 3 7 | | | +--------+ +--------+ +--------+ +--------+ | | +--------+ +--------+ +--------+ +--------+ | | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | | +--------+ +--------+ +--------+ +--------+ | | +--------+ +--------+ +--------+ +--------+ | | | 256 kB | | 256 kB | | 256 kB | | 256 kB | | | +--------+ +--------+ +--------+ +--------+ | | +-----------------------------------------+ | | | 8 MB | | | +-----------------------------------------+ | +---------------------------------------------+ |
If we compare the above information with lscpu output then most of the information is self-explanatory. Note that we have added annotations of the form (X) on the right to describe various sections. Here is a brief summary:
- (1) shows CPU information and base frequency. (stepping level indicates a number of improvements made to the product for functional (bug) fixes or manufacturing improvements).
- (2) shows information about the number of sockets, number of physical cores per socket, and number of hardware threads per core.
- (3) shows information about the association of hardware threads to physical core and sockets. It also shows if a particular core is online or offline. (You can mark particular core online or offline by writing 0 or 1 to
/sys/devices/system/cpu/cpu*/online). - (4) shows information about sockets and which hardware threads or cores it contains.
- (5) shows different cache levels, their sizes, and how they shared by hardware threads or physical cores. For example, Level 1 cache level is 32 kB and each physical core has a separate 32 kB block. This is indicated by cache groups like
( 0 4 )which are two hardware threads of physical Core 0. - (6) shows NUMA domain information and memory size. As this node has a single NUMA domain, Domain 0 comprises all cores and NUMA distance is minimum i.e. 10.
- Finally, (7) shows graphical topology information which is easy to comprehend. The first physical core has two hyperthreads (0, 4) and it has a private L1 cache of 32 KB and a private L2 cache of 256 KB. The last level cache of 8 MB is shared across all 4 cores. This is especially helpful when you have a multi-socket compute node and you don't need to scan all textual output.
You can find additional information about the likwid-topology tool here.
2. Understanding the topology of a multi-socket node with GPUs
likwid-topology becomes more handy and intuitive as compute node gets more complex. Let's look at an example of a dual-socket compute node with 4 NVIDIA GPUs. The output is trimmed for brevity:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 |
$ likwid-topology -g -------------------------------------------------------------------------------- CPU name: Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz CPU type: Intel Cascadelake SP processor CPU stepping: 7 ******************************************************************************** Hardware Thread Topology ******************************************************************************** Sockets: 2 Cores per socket: 20 (1) Threads per core: 2 -------------------------------------------------------------------------------- HWThread Thread Core Socket Available 0 0 0 0 * 1 0 1 0 * 2 0 2 0 * 3 0 3 0 * ... 18 0 18 0 * 19 0 19 0 * 20 0 20 1 * 21 0 21 1 * ... 38 0 38 1 * 39 0 39 1 * (2) 40 1 0 0 * 41 1 1 0 * ... 58 1 18 0 * 59 1 19 0 * 60 1 20 1 * 61 1 21 1 * ... 78 1 38 1 * 79 1 39 1 * -------------------------------------------------------------------------------- Socket 0: ( 0 40 1 41 2 42 3 43 4 44 5 45 6 46 7 47 8 48 9 49 10 50 11 51 12 52 13 53 14 54 15 55 16 56 17 57 18 58 19 59 ) Socket 1: ( 20 60 21 61 22 62 23 63 24 64 25 65 26 66 27 67 28 68 29 69 30 70 31 71 32 72 33 73 34 74 35 75 36 76 37 77 38 78 39 79 ) -------------------------------------------------------------------------------- ******************************************************************************** Cache Topology ******************************************************************************** Level: 1 Size: 32 kB Cache groups: ( 0 40 ) ( 1 41 ) ( 2 42 ) ( 3 43 ) ( 4 44 ) ( 5 45 ) ( 6 46 ) ( 7 47 ) ( 8 48 ) ( 9 49 ) ( 10 50 ) ( 11 51 ) ( 12 52 ) ( 13 53 ) ( 14 54 ) ( 15 55 ) ( 16 56 ) ( 17 57 ) ( 18 58 ) ( 19 59 ) ( 20 60 ) ( 21 61 ) ( 22 62 ) ( 23 63 ) ( 24 64 ) ( 25 65 ) ( 26 66 ) ( 27 67 ) ( 28 68 ) ( 29 69 ) ( 30 70 ) ( 31 71 ) ( 32 72 ) ( 33 73 ) ( 34 74 ) ( 35 75 ) ( 36 76 ) ( 37 77 ) ( 38 78 ) ( 39 79 ) -------------------------------------------------------------------------------- Level: 2 Size: 1 MB Cache groups: ( 0 40 ) ( 1 41 ) ( 2 42 ) ( 3 43 ) ( 4 44 ) ( 5 45 ) ( 6 46 ) ( 7 47 ) ( 8 48 ) ( 9 49 ) ( 10 50 ) ( 11 51 ) ( 12 52 ) ( 13 53 ) ( 14 54 ) ( 15 55 ) ( 16 56 ) ( 17 57 ) ( 18 58 ) ( 19 59 ) ( 20 60 ) ( 21 61 ) ( 22 62 ) ( 23 63 ) ( 24 64 ) ( 25 65 ) ( 26 66 ) ( 27 67 ) ( 28 68 ) ( 29 69 ) ( 30 70 ) ( 31 71 ) ( 32 72 ) ( 33 73 ) ( 34 74 ) ( 35 75 ) ( 36 76 ) ( 37 77 ) ( 38 78 ) ( 39 79 ) -------------------------------------------------------------------------------- Level: 3 Size: 28 MB Cache groups: ( 0 40 1 41 2 42 3 43 4 44 5 45 6 46 7 47 8 48 9 49 10 50 11 51 12 52 13 53 14 54 15 55 16 56 17 57 18 58 19 59 ) ( 20 60 21 61 22 62 23 63 24 64 25 65 26 66 27 67 28 68 29 69 30 70 31 71 32 72 33 73 34 74 35 75 36 76 37 77 38 78 39 79 ) -------------------------------------------------------------------------------- ******************************************************************************** NUMA Topology (3) ******************************************************************************** NUMA domains: 2 -------------------------------------------------------------------------------- Domain: 0 Processors: ( 0 40 1 41 2 42 3 43 4 44 5 45 6 46 7 47 8 48 9 49 10 50 11 51 12 52 13 53 14 54 15 55 16 56 17 57 18 58 19 59 ) Distances: 10 21 Free memory: 374531 MB Total memory: 392892 MB -------------------------------------------------------------------------------- Domain: 1 Processors: ( 20 60 21 61 22 62 23 63 24 64 25 65 26 66 27 67 28 68 29 69 30 70 31 71 32 72 33 73 34 74 35 75 36 76 37 77 38 78 39 79 ) Distances: 21 10 Free memory: 368780 MB Total memory: 393216 MB -------------------------------------------------------------------------------- ******************************************************************************** GPU Topology ******************************************************************************** (4) GPU count: 4 -------------------------------------------------------------------------------- ID: 0 Name: Tesla V100-PCIE-32GB Compute capability: 7.0 L2 size: 6.00 MB Memory: 32.00 GB SIMD width: 32 Clock rate: 1380000 kHz Memory clock rate: 877000 kHz Attached to NUMA node: 0 ... -------------------------------------------------------------------------------- ID: 3 Name: Tesla V100-PCIE-32GB Compute capability: 7.0 L2 size: 6.00 MB Memory: 32.00 GB SIMD width: 32 Clock rate: 1380000 kHz Memory clock rate: 877000 kHz Attached to NUMA node: 0 -------------------------------------------------------------------------------- ******************************************************************************** Graphical Topology (5) ******************************************************************************** Socket 0: +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ | | | 0 40 | | 1 41 | | 2 42 | | 3 43 | | 4 44 | | 5 45 | | 6 46 | | 7 47 | | 8 48 | | 9 49 | | 10 50 | | 11 51 | | 12 52 | | 13 53 | | 14 54 | | 15 55 | | 16 56 | | 17 57 | | 18 58 | | 19 59 | | | +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ | | +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ | | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | | +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ | | +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ | | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | | +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ | | +-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | | | 28 MB | | | +-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ Socket 1: +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ | | | 20 60 | | 21 61 | | 22 62 | | 23 63 | | 24 64 | | 25 65 | | 26 66 | | 27 67 | | 28 68 | | 29 69 | | 30 70 | | 31 71 | | 32 72 | | 33 73 | | 34 74 | | 35 75 | | 36 76 | | 37 77 | | 38 78 | | 39 79 | | | +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ | | +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ | | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | 32 kB | | | +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ | | +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ | | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | 1 MB | | | +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ +--------+ | | +-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | | | 28 MB | | | +-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ |
The above output is familiar to us. We will highlight major differences due to dual socket and GPUs:
- (1) shows that there are two sockets with 20 physical cores each. Each physical core has two hardware threads as hyperthreading is enabled.
- (2) shows hardware thread topology. Physical cores 0 to 19 are part of the first socket and 20 to 39 are part of the second socket. The hardware threads from 40 to 59 and 60 to 79 represent hyperthreads corresponding to the first and second socket respectively.
- (3) shows that there are two NUMA domains corresponding to two sockets. The
Distancesmetric shows that there is extra cost access memory across NUMA domains. This also confirms that there are two different physical NUMA domains. - (4) shows information about GPUs available on the node. There are four V100 NVIDIA GPUs and various hardware properties like L2 cache size, memory size, frequency are shown.
- (5) shows the graphical topology of the node. This is a quick way to capture the overall topology of the node. You might have noticed that the GPUs are not shown in this graphical topology.
This should have provided you a good overview of what to expect from likwid-topology. You can look at more examples on LIKWID Wiki page. Note that in order to detect GPUs, GPU support needs to be enabled at install time and CUDA + CUPTI libraries must be available (e.g. using LD_LIBRARY_PATH).
3. Thread affinity domains in LIKWID
Every few months I return to LIKWID and forget or mix naming conventions. So in the next few sections, we will look into some of the common terminology and syntax used with LIKWID.
LIKWID has the concept of thread affinity domains which is nothing but a group of cores sharing some physical entity. Here are four different affinity domains:
- N : represents a node and includes all cores in a given compute node
- S : represents socket and include all cores in a given socket
- C : represents last level cache and include all cores sharing last level cache
- M : represents NUMA domain and includes all cores in a given NUMA domain
These domains can be well explained by an example. One can use likwid-pin tool to list available domains on a given compute node:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
$ likwid-pin -p Domain N: 0,40,1,41,2,42,3,43,4,44,5,45,6,46,7,47,8,48,9,49,10,50,11,51,12,52,13,53,14,54,15,55,16,56,17,57,18,58,19,59,20,60,21,61,22,62,23,63,24,64,25,65,26,66,27,67,28,68,29,69,30,70,31,71,32,72,33,73,34,74,35,75,36,76,37,77,38,78,39,79 Domain S0: 0,40,1,41,2,42,3,43,4,44,5,45,6,46,7,47,8,48,9,49,10,50,11,51,12,52,13,53,14,54,15,55,16,56,17,57,18,58,19,59 Domain S1: 20,60,21,61,22,62,23,63,24,64,25,65,26,66,27,67,28,68,29,69,30,70,31,71,32,72,33,73,34,74,35,75,36,76,37,77,38,78,39,79 Domain C0: 0,40,1,41,2,42,3,43,4,44,5,45,6,46,7,47,8,48,9,49,10,50,11,51,12,52,13,53,14,54,15,55,16,56,17,57,18,58,19,59 Domain C1: 20,60,21,61,22,62,23,63,24,64,25,65,26,66,27,67,28,68,29,69,30,70,31,71,32,72,33,73,34,74,35,75,36,76,37,77,38,78,39,79 Domain M0: 0,40,1,41,2,42,3,43,4,44,5,45,6,46,7,47,8,48,9,49,10,50,11,51,12,52,13,53,14,54,15,55,16,56,17,57,18,58,19,59 Domain M1: 20,60,21,61,22,62,23,63,24,64,25,65,26,66,27,67,28,68,29,69,30,70,31,71,32,72,33,73,34,74,35,75,36,76,37,77,38,78,39,79 |
In the above example, each physical core is shown with two hyperthreads as hyperthreading is enabled. For example, (0,40) represents the physical core 0, (1,41) represents the physical core 1, and so on. The N represents the entire compute node comprising all physical and logical cores from 0 to 69. The S0 and S1 represent two sockets within the compute node N. The L3 cache is shared by all cores of individual sockets and hence there are two groups C0 and C1. Each socket has local DRAM and hence there are two memory domains M0 and M1.
4. How to pin threads to hyperthreads, cores, sockets or NUMA domains
Pinning threads to the right cores is important for application performance. LIKWID provides a tool called likwid-pin that can be used to pin application threads more conveniently. It works with all threading models that use Pthread underneath and executables that are dynamically linked.
likwid-pin can be used as:
|
1 2 3 |
likwid-pin -c < pin-options > ./app arguments |
where pin-options are CPU cores specification. Lets look at the examples of <pin-options> that will help to understand the syntax better:
N:0-9: represent 10 physical cores in a node (noticeNwhich decide domain to entire node). As we have two sockets in a node, the first 5 physical cores from each socket will be selected. Note that for all logical numbering schemes physical cores are selected first.S0:0-9: represent the first 10 physical cores in the first socket (noticeS0which decide 0th socket in the node).C1:0-9: represent the first 10 physical cores sharing shared L3 cache. This will be the same asS1:0-9i.e. 10 physical cores in the second socket.S0:0-9@S1:10-19: represent first 10 physical cores from the first socketS0and the last 10 physical cores from the second socketS1. The@can be used to chain multiple expressions.E:S0:10: represents expression based syntax where 10 cores from the first socket with compact ordering. This means, as hyperthreading is enabled, the first 5 physical cores are selected and threads are pinned to each hyperthread. The expression based syntax has formE:<thread domain>:<number of threads>.E:S0:20:1:2: represents expression based syntax of formE:<thread domain>:<number of threads>:<chunk size>:<stride>. In this case, in the first socketS0, we are selecting 1 core (as chunk size) after every 2 cores (as stride) and in total 20 cores. If we look at the output oflikwid-pinshown above, this means we are selecting0,1,2,3,4....19which is all physical cores in the first socket i.e.S0:0-19.M:scatter: scatter threads across all NUMA domains. First physical cores from each NUMA domain will be selected alternatively and then hyperthreads on both sockets. In above example, it will result into following selection:0,20,1,21,2,22....19,39,40,60,41,61...59,79.0,2-3: represent CPU cores with Ids 0, 2 and 3. Note that we are not using domain prefix here but directly specifying physical CPU Ids and hence this is called physical numbering scheme.
The reason for covering these all syntaxes in one section is that they used in this blog post but also in other LIKWID tutorials. So this section pretty much covers all necessary pinning-related syntaxes that one needs to know.
5. likwid-bench : A microbenchmarking framework
One of the tools that make LIKWID quite unique compared to other profiling tools is likwid-bench. Like older LLCbench and LMbench tools, the goal of likwid-bench is to provide microbenchmarking tool that can help to gain insight into the microarchitecture details. It also serves as a framework to easily prototype multi-threaded benchmarking kernels written in assembly language. We will not go into too many details in this blog post but you can read the details in this manuscript and the wiki page.
We can list available microbenchmarks using -a option:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
$ likwid-bench -a clcopy - Double-precision cache line copy, only touches first element of each cache line. clload - Double-precision cache line load, only loads first element of each cache line. clstore - Double-precision cache line store, only stores first element of each cache line. copy - Double-precision vector copy, only scalar operations daxpy - Double-precision linear combination of two vectors, only scalar operations ddot - Double-precision dot product of two vectors, only scalar operations divide - Double-precision vector update, only scalar operations load - Double-precision load, only scalar operations peakflops - Double-precision multiplications and additions with a single load, only scalar operations store - Double-precision store, only scalar operations stream - Double-precision stream triad A(i) = B(i)*c + C(i), only scalar operations sum - Double-precision sum of a vector, only scalar operations triad - Double-precision triad A(i) = B(i) * C(i) + D(i), only scalar operations update - Double-precision vector update, only scalar operations |
Note that the above list is not complete but we are only showing main benchmark categories. Each benchmark is implemented with different instruction sets (e.g. SSE, AVX2, AVX512, ARM NEON, Power VSX, ARM SVE) depending upon the target ISA. You can see the platforms and their implementation under bench sub-directory. You can get information about each kernel using likwid-bench -l command. In the next sections, we will use these microbenchmarks to measure performance metrics like flops and memory bandwidth.
6. Understanding workgroups in the likwid-bench
When we run a microbenchmark with likwid-bench, we have to select affinity domain, data set size and number of threads. These resources collectively called workgroup. For example, if we want to run STREAM benchmark on a specific socket S, using N cores and M amount of memory then this is one workgroup. User can select multiple workgroup for a single execution of the benchmark. The workgroup has syntax of <domain>:<size>:<num_threads>:<chunk_size>:<stride>. The size can be specified in either kB, KB, MB or GB. Lets look at some examples:
-w S0:100kB: run microbenchmark using 100kB data allocated in the first socket S0. As number of threads are not specified, it will use all threads in domain S0 i.e. 40 threads in our case. Note that by default threads are placed on their local socket.-w S1:1MB:2: run microbenchmark using 1MB of data allocated in the second socket S1 and first two physical cores i.e. 20 and 21 in the second socket.-w S0:1GB:20:1:2: run microbenchmark using 1GB of data allocated in first socket S0. Run one thread after every two cores and run in total 20 threads. As discussed inlikwid-pin, this will will select all physical cores on the first socket S0.-w S0:20kB:1 -w S1:20kB:1: run microbenchmark using one thread running on first physical cores in each socket with 20kB data allocated.-w S1:1GB:2-0:S0,1:S0: run microbenchmark with 1GB of data allocated in first socket S0 but 2 threads are running in the second socket S1. Note that the streams specified with0:S0and1:S0indicates where the data is being allocated. As you might have guessed, intention here is to find out the cost of memory access from another socket / NUMA domain. We will see example of this later in the benchmarks.
We will use these workgroups in the next sections to run different microbenchmarks.
7. Understanding structure and output of likwid-bench
We are going to use likwid-bench to answer a number of questions and hence it will be helpful to understand various metrics provided by likwid-bench. First, let's look at a very high-level structure of how a particular microbenchmark is executed under likwid-bench (see implementation here). This will help to understand some of the metrics shown by likwid-bench:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
.... // LIKWID Markup Begin : Start Counter Measurement // iteration count based on user input or minimum time to // run a benchmark every thread execute all iterations for(outer loop iterations ) { // iteration count based on the workgroup size for (innrer loop iterations) { // microbenchmark kernel block { // kernel written in assembly code // e.g. unrolled STREAM A(i) = B(i)*c + C(i) A(i+1) = B(i+1)*c + C(i+1) A(i+2) = B(i+2)*c + C(i+2) A(i+3) = B(i+3)*c + C(i+3) } } } // LIKWID Markup End : Stop Counter Measurement .... |
The structure is quite self-explanatory: 1) counters measurement is started at the beginning of benchmark 2) LIKWID decides a number of repetitions to execute based on either user input or minimum execution time for which benchmark should be run 3) inner loop iterations of a benchmark is determined by working set size i.e. size of input provided by user 4) and finally a microbenchmark written in assembly code is executed repeatedly. Note that the kernel code might have been unrolled and hence one execution of a kernel code could be executing multiple iterations.
Before running various benchmarks and generating lots of numbers, it's very important to understand individual metrics reported by likwid-bench. Let's start with the STREAM benchmark. In LIKWID there are multiple implementations (stream, stream_avx, stream_avx512, stream_avx512_fma) based on instruction sets. For simplicity, we will select the basic implementation without any vector instructions. Using the workgroup syntax, we are going to use 2 threads pinned to the first socket S0, and allocate 32 KB of data. We are running only 10 iterations so that we can calculate various metrics by hand:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
$ likwid-bench -i 10 -t stream -w S0:32KB:2 ... Warning: Sanitizing vector length to a multiple of the loop stride 4 and thread count 2 from 1333 elements (10664 bytes) to 1328 elements (10624 bytes) ... -------------------------------------------------------------------------------- LIKWID MICRO BENCHMARK Test: stream -------------------------------------------------------------------------------- Using 1 work groups Using 2 threads ... Group: 0 Thread 1 Global Thread 1 running on hwthread 40 - Vector length 664 Offset 664 Group: 0 Thread 0 Global Thread 0 running on hwthread 0 - Vector length 664 Offset 0 ---------------------------------------------------------------------------- Cycles: 32554 (1) CPU Clock: 2494121832 (2) Cycle Clock: 2494121832 (3) Time: 1.305229e-05 sec (4) Iterations: 20 (5) Iterations per thread: 10 (6) Inner loop executions: 166 (7) Size (Byte): 31872 (8) Size per thread: 15936 (9) Number of Flops: 26560 (10) MFlops/s: 2034.89 (11) Data volume (Byte): 318720 (12) MByte/s: 24418.70 (13) Cycles per update: 2.451355 (14) Cycles per cacheline: 19.610843 (15) Loads per update: 2 (16) Stores per update: 1 (17) Load bytes per element: 16 (18) Store bytes per elem.: 8 (19) Load/store ratio: 2.00 (20) Instructions: 63097 (21) UOPs: 86320 (22) --------------------------------------------------------------------------- |
Note that in the above output we have annotated each metric with a number on the right-hand side which we will use as a reference below. Let's go through the metrics one by one (see wiki here) and compare them with the above results:
- (1) Cycles: number of cycles measured with RDTSC instruction. Modern CPUs don't have fixed clocks but they vary (e.g. due to turbo boost, power management unit). Comparing two measurements with cycles as metric doesn't make sense as a clock can slow down or speed up at runtime. To avoid this, LIKIWID measures cycles using the RDTSC instruction which is clock invariant. In the above example, measured
Cyclesare 36856. - (2) CPU Clock: CPU frequency at the beginning of the benchmark execution. The Cascadelake CPU we are running has a base frequency of 2.3 GHz. The number determined by LIKWID, 2.294 GHz, is quite close.
- (3) Cycle clock: the frequency used to count
Cyclesmetric. In our case, this is the same asCPU Clock. - (4) Time: runtime of the benchmark calculated using
CyclesandCycle clockmetrics. We are running a very small workload (1.6e-6 sec) for demonstration purposes. In a real benchmark, one should run larger iterations to get stable numbers and avoid benchmarking overheads. - (5) Iterations: sum of outer loop iterations across all threads (see benchmark structure shown above). On the command line, we have specified 10 iterations (i.e.
-i 10). As we have two threads, the total number of iterations is 20. Note that even though iterations are increased with threads, the total work remains the same asInner loop executionsare reduced proportionally. - (6) Iterations per thread: number of outer loop iterations per thread.
- (7) Inner loop executions: number of inner loop iterations for a given working set size. Note that this is not the total number of inner loop executions but the trip count of the inner loop for a single iteration of the outer loop. If we increase the number of threads then input data size per thread reduces and hence the trip count of the inner loop also reduces.
- (8) Size (Byte): total size of input data in bytes for all threads. Note that LIKWID "sanitize" the length of vectors to be multiple of loop stride (as kernel might be unrolled). So the data size used by LIKWID could be slightly less than the user input. For example, in our example, we specified 32KB as a working set size. The STREAM benchmark requires three vectors. LIKWID select 1328 elements i.e. 1328 elements x 8 bytes per double x 3 vectors = 31872 bytes instead of 32768 bytes (i.e. 32KB).
- (9) Size per thread: the size of input data in bytes per thread.
Size (Byte)is equally divided across threads. - (10) Number of Flops: number of floating-point operations executed during the benchmark. In the case of STREAM benchmark, we have 2 flops per element and the inner loop is unrolled four times. So the total number of flops = 166 iterations x 4 unroll factor x 2 flops per element x 10 iterations i.e. 26560.
- (11) MFlops/s: millions of floating-point operations per second (
Number of Flops/Time). - (12) Data volume (Byte): the amount of data processed by all threads (
Size (Byte)*Iterations per thread). Note that this doesn't include the "hidden" data traffic (e.g. write-allocate, prefetching). - (13) MByte/s: bandwidth achieved during the benchmark i.e.
Data volume (Byte)/Time - (14) Cycles per update: number of CPU cycles required to update one item in the result cache line. For example, if we need to load 2 cache lines to write one cache line of result then the reading of two values and writing a single value is referred to as "one update".
- (15) Cycles per cacheline: number of CPU cycles required to update the result of the whole cache line.
- (16) Loads per update: number of data items needs to be loaded for "one update".
- (17) Stores per update: number of stores performed for "one update".
- (18) Load bytes per element: amount of data loaded for "one update". In case of STREAM benchmark there are two loads per update i.e.
B[i]andC[i]. - (19) Store bytes per elem.: the amount of data stored for "one update". In the case of STREAM, there is a single store i.e.
A[i]. - (20) Load/store ratio: ratio of the amount of data loaded and stored (
Load bytes per element/Store bytes per elem.) - (21) Instructions: number of instructions executed during the benchmark. Note that this instruction count is statistically calculated from the benchmarking kernel in assembly language.
- (22) UOPs: Amount of micro-ops executed during the benchmark. Note that this
uOpscount is not measured at runtime but statitically calculated from the information provided in the assembly kernel.
8. How to measure the peak performance of a CPU (FLOPS)?
Let's now see how likwid-bench can be used to answer quite some interesting questions about a particular CPU. In this section, let's try to understand theoretical peak performance and verify it with practical measurements. For a Cascadelake 6248 CPU @ 2.5GHz supporting AVX-512 instructions and 2 FMA units, the theoretical performance can be calculated as:
|
1 2 3 |
8 (vector width) x 2 (ops per FMA) x 2 (FMA units) x 2.5e9 (GHz) = 80.0 GFlops/s |
likwid-bench provides peakflops_avx512_fma microbenchmark that can be used to calculate peak flops performance with AVX-512 and FMA instructions. As we want to measure peak compute performance, we want to avoid any memory access cost by using the dataset size that fits into L1 cache i.e. 32 KB. In the below output we are showing only relevant metrics for brevity:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
$ likwid-bench -t peakflops_avx512_fma -w S0:32KB:1 Allocate: Process running on hwthread 0 (Domain S0) - Vector length 4000/32000 Offset 0 Alignment 512 -------------------------------------------------------------------------------- LIKWID MICRO BENCHMARK Test: peakflops_avx512_fma -------------------------------------------------------------------------------- Using 1 work groups Using 1 threads Cycles: 3987091656 CPU Clock: 2494117254 Cycle Clock: 2494117254 Time: 1.598598e+00 sec Iterations: 1048576 Iterations per thread: 1048576 Inner loop executions: 500 Size (Byte): 32000 Size per thread: 32000 Number of Flops: 125829120000 MFlops/s: 78712.16 -------------------------------------------------------------------------------- |
We can see that the achieved performance, 78.7 GFlops/s, is quite close to what we calculated by hand! Also, the throughput (Number of Flops / Cycles ) is 125829120000 / 3987091656 = ~31.6 close to the theoretical 32 flops (8 [double vector width] x 2 [ops per FMA] x 2 [FA units]).
Let's now measure the peak flops performance of single socket and two sockets (i.e. whole node). We are now starting to use workgroup syntax more and more. If you have any questions regarding workgroup syntax then scroll back to the Section 6:
|
1 2 3 4 5 6 7 8 9 10 |
# run benchmark with 20 threads pinned to 20 physical cores of the first socket and using 32KB data per thread $ likwid-bench -t peakflops_avx512_fma -w S0:640KB:20:1:2 | grep MFlops MFlops/s: 1562731.25 # run benchmark with two workgroups: each workgroup per socket with 20 threads selected alternatively # (one thread with a stride of two i.e. all physical cores) and using 32 KB data per thread $ likwid-bench -t peakflops_avx512_fma -w S0:640KB:20:1:2 -w S1:640KB:20:1:2 | grep MFlops MFlops/s: 3111830.37 |
With 80 GFlops/s theoretical peak performance per core, upper bounds for single socket (20 cores) and two sockets (40 cores) are 1.6 TFlops/s and 3.2 TFlops/s respectively. The measured performances of 1.5 TFlops/s and 3.1 TFlops/s using likwid-bench are quite close to theoretical peaks. If you wonder about how these kernels are implemented then you should jump into the assembly kernels e.g. peakflops_avx512_fma.ptt. These implementations are a great resource if you want to understand how to develop microbenchmarks to attain peak performance.
9. Do we get better FLOPS with Hyper-Threading?
We have heard that hyperthreading is not always beneficial and it might even make an application run slower. Why is that? The reason is that with hyperthreading two threads are executed on a single physical core. The CPU can interleave the instructions from two threads and able to fill the pipeline bubbles. This is helpful in the case of long-latency memory accesses and can improve the overall throughput. But, when we have a well-optimized compute kernels utilizing all core resources and without memory stalls then the hyperthreading won't help and could just add some overhead from the thread scheduling.
We can verify this with likewid-bench. Let's use again peakflops_avx512_fma microbenchmark with the input data fitting in the L1 cache so that there are no stalls from memory accesses:
|
1 2 3 4 5 6 7 8 9 |
# one thread pinned to single physical core $ likwid-bench -t peakflops_avx512_fma -w S0:32KB:1 | grep MFlops/s MFlops/s: 78667.27 # two cores are selected with a stride of 40 i.e. first physical core with two hyper threads (i.e. 0 and 40) $ likwid-bench -t peakflops_avx512_fma -w S0:32KB:2:1:40 | grep MFlops/s MFlops/s: 78057.60 |
As we can see above, the achieved performance for a single thread is 78.6 GFlops/s whereas two hyperthreads achieve 78.05 GFlops/s. So no real gain from Hyper-Threading here.
Note: these numbers are close and in practice, we should re-run such benchmark multiple times for stable results. But the goal here is to show methodology instead of discussion numbers too much.
10. How much is the performance impact of vectorization (SIMD) on flops performance?
Modern CPUs have support for vector operations with SIMD instructions. For example, on the X86 platform, going from SSE to AVX2 to AVX-512 increases vector registers width from 128 to 256 to 512 bits respectively. A 512-bit register can hold 8 64-bit double-precision values and perform calculations 8 times faster. But how to measure this easily in practice? To answer this we can use peak_flops benchmarks implemented using various instruction sets:
|
1 2 3 4 5 6 7 8 9 10 |
# list double-precision flops benchmarks (excluding single prevision benchmarks) $ likwid-bench -a | grep flops | grep -v "_sp" peakflops - Double-precision multiplications and additions with a single load, only scalar operations peakflops_avx - Double-precision multiplications and additions with a single load, optimized for AVX peakflops_avx512 - Double-precision multiplications and additions with a single load, optimized for AVX- peakflops_avx512_fma - Double-precision multiplications and additions with a single load, optimized for AVX- peakflops_avx_fma - Double-precision multiplications and additions with a single load, optimized for AVX FMAs peakflops_sse - Double-precision multiplications and additions with a single load, optimised for SSE |
As Cascade Lake supports SSE, AVX and AVX-512 instructions, we can run peak_flops with different instructions set as:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# loop over different versions and extract only flops metric $ for bench in peakflops peakflops_sse peakflops_avx peakflops_avx_fma peakflops_avx512 peakflops_avx512_fma; \ do \ likwid-bench -t $bench -w S0:32KB:1 | grep MFlops/s; \ done MFlops/s: 6365.88 MFlops/s: 12715.50 MFlops/s: 22118.26 MFlops/s: 44313.04 MFlops/s: 39382.22 MFlops/s: 78725.05 |
In the above output we can see that going from serial version to SSE to AVX and AVX-512 implementation improves performance by almost factor of two. We will not dive into details of each implementation but you can see the respective implementations here: peakflops, peakflops_sse, peakflops_avx, peakflops_avx_fma, peakflops_avx512 and peakflops_avx512_fma.
11. How to measure the peak memory bandwidth of a CPU? How important is vectorization for bandwidth performance?
The performance of many scientific applications is limited by memory bandwidth and hence it is one of the most important metrics in scientific computing. Hence, analyzing bandwidth bottlenecks at different memory hierarchies is critical to understand the suitability of a given hardware platform for a diverse set of applications. In this section, we are going to see how to measure memory bandwidth across different memory hierarchies.
The Cascadelake processors connect to the main memory through six channels, each with a single DDR4-2933 MHz DIMM. The theoretical peak memory bandwidth of a dual-socket compute node can be calculated as:
|
1 2 3 |
2.933 Giga Transfers/s * 8 bytes per channel x 6 channels x 2 sockets = ~281 GB/s |
In practice, the achievable bandwidth is quite low than the theoretical peak and the STREAM benchmark is commonly used to measure the same. We will use triad kernel (A[i] = B[i] + scalar*C[i]) from STREAM benchmark. Based on CPU instruction sets, likwid-bench provides various implementations and you can see them as:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# list only double precision triad benchmark $ likwid-bench -a | grep "triad_" | grep -v "_sp" triad_avx - Double-precision triad A(i) = B(i) * C(i) + D(i), optimized for AVX triad_avx512 - Double-precision triad A(i) = B(i) * C(i) + D(i), optimized for AVX- triad_avx512_fma - Double-precision triad A(i) = B(i) * C(i) + D(i), optimized for AVX- triad_avx_fma - Double-precision triad A(i) = B(i) * C(i) + D(i), optimized for AVX FMAs triad_mem_avx - Double-precision triad A(i) = B(i) * C(i) + D(i), uses AVX and non-temporal stores triad_mem_avx512 - Double-precision triad A(i) = B(i) * C(i) + D(i), uses AVX- triad_mem_avx512_fma - Double-precision triad A(i) = B(i) * C(i) + D(i), optimized for AVX- triad_mem_avx_fma - Double-precision triad A(i) = B(i) * C(i) + D(i), optimized for AVX FMAs and non-temporal stores triad_mem_sse - Double-precision triad A(i) = B(i) * C(i) + D(i), optimized for SSE and non-temporal stores triad_mem_sse_fma - Double-precision triad A(i) = B(i) * C(i) + D(i), optimized for SSE FMAs and non-temporal stores triad_sse - Double-precision triad A(i) = B(i) * C(i) + D(i), optimized for SSE triad_sse_fma - Double-precision triad A(i) = B(i) * C(i) + D(i), optimized for SSE FMAs |
We will use AVX-512 implementation with non-temporal stores and pin a single thread per physical core with 1GB data. Note that we have used here likwid-pin tool to pin threads to 40 physical cores in Node domain:
|
1 2 3 4 |
$ likwid-pin -c N:0-39 likwid-bench -t triad_mem_avx512_fma -w S0:10GB:20 -w S1:10GB:20 | grep MByte/s MByte/s: 197395.55 |
In practice, the achievable bandwidth is around 210 GB/s (see various configurations presented in this article by Dell Inc). In our case, without configuration changes or tuning, the achieved performance of 197 GB/s is quite good. If you are curious about performance details, see this manuscript where the performance of different HPC benchmarks is compared on Intel Broadwell and Cascade Lake processor.
We can also run serial, SSE, AVX, AVX-512 versions of triad benchmark to see the effect of vector instructions on the bandwidth performance:
|
1 2 3 4 5 6 7 8 9 10 11 |
$ for bench in triad triad_mem_sse_fma triad_mem_avx_fma triad_mem_avx512_fma; \ do \ likwid-pin -c N:0-39 likwid-bench -t $bench -w S0:10GB:20 -w S1:10GB:20 | grep MByte/s; \ done MByte/s: 161261.81 MByte/s: 186469.17 MByte/s: 189225.99 MByte/s: 199139.93 |
It's apparent that the difference between SSE, AVX and AVX-512 on memory is bandwidth is small compared to what we saw for flops performance. This is expected because the bandwidth can be saturated easily. You can run the same benchmark with a single thread and see what you get!
12. How many cores can saturate the memory bandwidth? How to easily measure it?
Even though modern processors have more cores with higher clock rates, memory-bound applications don't scale well with the increasing cores. One of the reasons is that the memory bandwidth can be saturated easily by a smaller number of cores than the total available. So while determining the suitability of a particular CPU platform it is important to measure single thread memory bandwidth and bandwidth performance scaling with the increasing number of cores.
We can achieve this using likwid-bench by running STREAM benchmark and gradually increasing the number of threads. Like the previous section, let's run triad kernel from 1 to 20 threads on the first socket and extract memory bandwidth metric MByte/s:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# run stream triad benchmark from 1 to 20 cores and store bandwidth performance in data.txt $ for t in <code>seq 1 20</code>; \ do \ likwid-pin -c S0:0-19 likwid-bench -t triad_mem_avx512_fma -w S0:2GB:$t 2>&1 | grep "MByte/s" | tee -a data.txt; \ done MByte/s: 13015.47 MByte/s: 25305.94 MByte/s: 37122.18 MByte/s: 48353.95 MByte/s: 59803.17 MByte/s: 70888.07 MByte/s: 81120.39 MByte/s: 87645.29 MByte/s: 92266.53 MByte/s: 96016.83 MByte/s: 98538.55 MByte/s: 100071.38 MByte/s: 100759.21 MByte/s: 101520.76 MByte/s: 101068.01 MByte/s: 101256.78 MByte/s: 101070.82 MByte/s: 100766.33 MByte/s: 99928.49 MByte/s: 99717.05 |
We can plot this data in a simple way on command line using gnuplot:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# take second column from the above data and plot using gnuplot on the terminal $ awk '{print $2}' data.txt | gnuplot -p -e "set terminal dumb; set xlabel '#cores'; plot '<cat' title 'Bandwidth'" 110000 +------+-----+------+-----+------+------+-----+------+-----+------+ | Bandwidth A + 100000 + A A A A A A A A A A + | A A | 90000 + A + | A | 80000 + + | A | 70000 + + 60000 + + | A | 50000 + + | A | 40000 + + | A | 30000 + + | A | 20000 + + A | 10000 +------+-----+------+-----+------+------+-----+------+-----+-----++ 0 2 4 6 8 10 12 14 16 18 20 #cores |
This is not a fancy plot but serves the purpose: around 10 cores the memory bandwidth is saturated and adding more cores doesn't improve performance any longer! This is great insight especially when we have memory-bound applications.
13. What is the performance difference between different cache levels? How to measure it?
The performance gap between the processor and memory is growing continuously (see also memory wall). The memory subsystem can not move data faster for all cores and hence optimally utilizing available caches is critical to hide long memory latencies. We know that the caches are faster and have higher bandwidths. But how fast are they? How much they can help? likwid-bench provides special cache line variants of microbenchmarks to measure data transfer capabilities inside the memory hierarchy. In below example we will use clcopy that performs simple vector copy A[i] = B[i]. We will use dataset sizes considering the different cache levels on Cascade Lake CPU:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# execution of clcopy with single thread pinned to the first socket $ for size in 32KB 1MB 28MB 1GB; do \ likwid-bench -t clcopy -w S0:$size:1 2>&1 | grep "MByte/s"; \ done MByte/s: 235439.40 MByte/s: 64867.40 MByte/s: 22050.44 MByte/s: 10982.82 |
As we go from data set fitting into L1 to L2 to L3 to main memory the memory bandwidth reduces from 235 GB/s to 64.8 GB/s to 22 GB/s to 10.9 GB/s. This easily demonstrates the importance of caches and how much performance improvements they can bring for bandwidth-limited applications. Note that we are not precisly looking into shared aspects of L3 cache and other architecture details. Our intention here is to introduce the capabilities of LIKWID and not to go through all details about specific platforms. To understand more details, ake a look at other tools like LMBench.
13. NUMA Effect: How to measure the performance impact?
We already know about NUMA: a processor can access its own local memory faster than non-local memory on another socket. In the case of Intel CPUs, multiple NUMA domains are connected via UPI. The Cascade Lake 6248 CPU support up to three UPI links operating at 10.4 GT/s. We can calculate maximum theoretical bandwidth across UPI link as:
|
1 2 3 4 |
10.4 GT/s x 3 UPI links x 2 (link width) = 62.4 GB/s // with 3 UPI links 10.4 GT/s x 2 UPI links x 2 (link width) = 41.4 GB/s // with 2 UPI links |
Considering theoretical bandwidth performance of ~140 GB/s per socket, there is more than a 2x performance penalty if we are accessing data from different NUMA domains. This is why we want to minimize such memory accesses. In practice, we can use likwid-bench to measure this performance impact. In order to do this, we can use the same triad_mem_avx512_fma microbenchmark and run it twice: 1) first, allocate 20GB of data on the first socket and run 20 threads on the first socket 2) second, allocate 20GB of data on the second socket and run 20 threads on the first socket:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# pin domain is the whole node but workgroup specifies 20 threads on first S0 socket and four # data streams for the data are also on first socket S0 $ likwid-pin -c N:0-39 likwid-bench -t triad_mem_avx512_fma -w S0:20GB:20-0:S0,1:S0,2:S0,3:S0 Cycles: 7995555762 Time: 3.198232e+00 sec MByte/s: 100055.29 Cycles per update: 0.799556 Cycles per cacheline: 6.396445 # pin domain is still whole node but four data streams are now pinned on second socket S1 $ likwid-pin -c N:0-39 likwid-bench -t triad_mem_avx512_fma -w S0:20GB:20-0:S1,1:S1,2:S1,3:S1 Cycles: 19063612050 Time: 7.625461e+00 sec MByte/s: 41964.68 Cycles per update: 1.906361 Cycles per cacheline: 15.250890 |
In the above example, we can see that the bandwidth is dropped from ~100 GB/s to ~41.9 GB/s. This is almost a 2.5x performance difference.
14. How to enable/disable turbo mode and change the CPU frequency?
For the benchmarking, we need to have stable performance numbers and one of the things to make sure is to fix the CPU core frequencies. LIKWID provides a tool called likwid-setFrequencies to manipulate processor core and uncore frequencies. Note that this could be disruptive to other users if you are using a shared compute node. If LIKWID is preinstalled, this tool might have been disabled or requires administrative permissions.
First, let's find out the current frequencies:
|
1 2 3 4 5 6 7 8 |
$ likwid-setFrequencies -p Current CPU frequencies: HWThread 0: governor performance min/cur/max 1.0/3.200073/3.9 GHz Turbo 1 HWThread 1: governor performance min/cur/max 1.0/3.200073/3.9 GHz Turbo 1 HWThread 2: governor performance min/cur/max 1.0/3.200073/3.9 GHz Turbo 1 ... |
We can see that the turbo mode is enabled and minimum/current/maximum frequencies are set to 1.0/3.200073/3.9 GHz respectively. Let's disable the turbo mode and set everything to a base frequency of 2.5GHz as:
|
1 2 3 4 5 6 7 8 |
$ likwid-setFrequencies -t 0 $ likwid-setFrequencies -p Current CPU frequencies: HWThread 0: governor performance min/cur/max 1.0/2.5/2.5 GHz Turbo 0 HWThread 1: governor performance min/cur/max 1.0/2.5/2.5 GHz Turbo 0 ... |
We can also change the min/max frequency for all cores. This is helpful when we want to choose a specific CPU SKU and want to find out the effect of CPU frequency on the application performance. For example, let's disable turbo mode and change frequencies from 1.0 GHz (min) to 2.5 GHz (base frequency) and see how peak flops performance changes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
$ likwid-setFrequencies -t 0; \ for freq in 1.0 1.4 1.8 2.2 2.5; \ do \ likwid-setFrequencies -t 0 -f $freq; \ likwid-bench -t peakflops_avx512_fma -w S0:32KB:1 | grep MFlops/s; \ done MFlops/s: 31451.79 MFlops/s: 43944.46 MFlops/s: 56777.03 MFlops/s: 69436.97 MFlops/s: 78913.09 |
If you compare the peak flops performance that we have calculated in Section 9 then these results are expected ones. This approach comes in very handy when you want to analyze the sensitivity of your application to CPU clock speed. You can enable turbo mode again and set min/max frequencies again using:
|
1 2 3 |
likwid-setFrequencies -x <min freq> -y <max freq> -t 1 |
15. How to measure power and energy consumption?
Many modern systems provide interfaces to measure CPU power and energy consumption. The interfaces are different for different CPU platforms. For example, Application Power Management (APM) for AMD CPUs, Running Average Power Limit (RAPL) for Intel CPUs, etc. The measurements provided by these interfaces could be actual readings or just estimates provided by power models. LIKWID provides a tool called likwid-powermeter that can record energy consumption of CPU and memory subsystem using RAPL interface (and hence not portable to other architectures). The RAPL is not an analog power meter but its software power model. But these measurements are close to real measurements (see this manuscript).
Let's run peak flops benchmark on a single socket with/without vector instructions and look at power consumption. Note that RAPL works per package (i.e. socket) and hence likwid-powermeter measurements are for the entire socket even if you are running the application on few cores.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# fix the cpu frequency without turbo mode $ likwid-setFrequencies -t 0 -f 2.5 # run peak flops AVX-512 benchmark and measures power on the first socket. # <code>-c 0</code> argumenet tells to do power measurements on first socket only $ likwid-powermeter -c 0 likwid-bench -t peakflops_avx512_fma -w S0:640KB:20:1:2 Cycles: 4017714124 MFlops/s: 1565923.69 -------------------------------------------------------------------------------- Runtime: 5.86463 s Domain PKG: Energy consumed: 469.481 Joules Power consumed: 80.053 Watt Domain DRAM: Energy consumed: 86.3252 Joules Power consumed: 14.7196 Watt -------------------------------------------------------------------------------- # run non-vectorized version of peak flops benchmark $ likwid-powermeter -c 0 likwid-bench -t peakflops -w S0:640KB:20:1:2 Cycles: 4216749916 MFlops/s: 99467.34 -------------------------------------------------------------------------------- Runtime: 6.12812 s Domain PKG: Energy consumed: 432.586 Joules Power consumed: 70.5904 Watt Domain DRAM: Energy consumed: 90.2036 Joules Power consumed: 14.7196 Watt |
In the above example, Domain PKG is CPU-related power consumption whereas Domain DRAM is the main memory-related power consumption. With AVX-512 the total energy consumed is slightly higher but at the same time, the MFlops/s is about ~15x higher and hence overall better energy efficiency. Note that the above example is just for demonstration purposes with a very small dataset fitting into cache and hence not driving much traffic to the memory subsystem. Also, this area is beyond my expertise. So I suggest referring to the wiki page and other relevant references.
16. Measuring performance counters with ease!
Let's begin with some clarifications as the above title might be a bit misleading - 1) with a diverse set of tools, measuring performance counters is becoming easy 2) but doing "right" measurements is still a challenge - you have to know what you are looking for and where to look for 3) after measurements, interpreting and making sense of the results is the hardest part. With tons of performance counters, low-level performance analysis is still somewhat art. Tools don't solve these problems magically, they just help us a bit!
One of the important parts of performance optimization is to understand how the application is interacting with a give CPU hardware. This is typically achieved via hardware performance counter analysis. The performance counters are a set of special-purpose registers built into modern microprocessors to count hardware-related activities. With different CPU platforms (Intel, AMD, ARM, IBM) it's becoming more and more complex to measure and interpret these low-level performance counters. LIKWID provides a tool called likwid-perfctr to ease this job.
likwid-perfctr can be used to measure performance counters for the entire application, a certain time duration, or a specific part of the code using Marker API (see next sections). Also, LIKWID has useful pre-selected event sets and derived metrics called performance groups. This helps new users to avoid the burden of knowing platform-specific hardware counters. These pre-configured groups can be queried as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
$ likwid-perfctr -a Group name Description -------------------------------------------------------------------------------- MEM_DP Overview of arithmetic and main memory performance UPI UPI data traffic TLB_INSTR L1 Instruction TLB miss rate/ratio TMA Top down cycle allocation CACHES Cache bandwidth in MBytes/s FLOPS_SP Single Precision MFLOP/s UOPS_EXEC UOPs execution UOPS_RETIRE UOPs retirement BRANCH Branch prediction miss rate/ratio FLOPS_AVX Packed AVX MFLOP/s L2CACHE L2 cache miss rate/ratio PMM Intel Optance DC bandwidth in MBytes/s L3 L3 cache bandwidth in MBytes/s ENERGY Power and Energy consumption L3CACHE L3 cache miss rate/ratio UOPS_ISSUE UOPs issueing MEM_SP Overview of arithmetic and main memory performance CYCLE_ACTIVITY Cycle Activities TLB_DATA L2 data TLB miss rate/ratio MEM Main memory bandwidth in MBytes/s DATA Load to store ratio L2 L2 cache bandwidth in MBytes/s DIVIDE Divide unit information FLOPS_DP Double Precision MFLOP/s CYCLE_STALLS Cycle Activities (Stalls) CLOCK Power and Energy consumption |
If you are curious about how these high-level metrics are calculated then you can look inside likwid/groups directory where metrics for each CPU type and respective hardware counters are listed in simple ASCII file (e.g. groups/CLX/FLOPS_DP.txt).
Let's try to look at few examples to get an idea of how likwid-perfctr can be helpful. We will run the peakflops_avx512_fma microbenchmark that we have run to calculate peak flops performance. Note that likwid-perfctr has pinning functionality inbuilt and hence we don't need to use likwid-pin separately. We have trimmed some of the metrics output for brevity:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
$ likwid-perfctr -C 0 -m -g FLOPS_DP likwid-bench -t peakflops_avx512_fma -w S0:32KB:1 ... Cycles: 3988127852 Time: 1.595258e+00 sec ... Number of Flops: 125829120000 (1) MFlops/s: 78876.98 ... Instructions: 9961472032 UOPs: 9437184000 -------------------------------------------------------------------------------- Region bench, Group 1: FLOPS_DP (2) +-------------------+------------+ | Region Info | HWThread 0 | +-------------------+------------+ | RDTSC Runtime [s] | 1.595259 | (3) | call count | 1 | +-------------------+------------+ +------------------------------------------+---------+-------------+ | Event | Counter | HWThread 0 | +------------------------------------------+---------+-------------+ | INSTR_RETIRED_ANY | FIXC0 | 10069480000 | | CPU_CLK_UNHALTED_CORE | FIXC1 | 3975550000 | (4) | CPU_CLK_UNHALTED_REF | FIXC2 | 3975583000 | | FP_ARITH_INST_RETIRED_128B_PACKED_DOUBLE | PMC0 | 0 | | FP_ARITH_INST_RETIRED_SCALAR_DOUBLE | PMC1 | 11 | | FP_ARITH_INST_RETIRED_256B_PACKED_DOUBLE | PMC2 | 0 | (5) | FP_ARITH_INST_RETIRED_512B_PACKED_DOUBLE | PMC3 | 15728640000 | +------------------------------------------+---------+-------------+ +----------------------+--------------+ | Metric | HWThread 0 | (6) +----------------------+--------------+ | Runtime (RDTSC) [s] | 1.5953 | (7) | Runtime unhalted [s] | 1.5902 | | Clock [MHz] | 2499.9334 | | CPI | 0.3948 | | DP [MFLOP/s] | 78876.9222 | | AVX DP [MFLOP/s] | 78876.9222 | (8) | AVX512 DP [MFLOP/s] | 78876.9222 | | Packed [MUOPS/s] | 9859.6153 | (9) | Scalar [MUOPS/s] | 6.895432e-06 | | Vectorization ratio | 100.0000 | (10) +----------------------+--------------+ |
Here is brief summary of what's being shown by ikwid-perfctr:
- we have launched
peakflops_avx512_fmabenchmark with 32 KB of the dataset and a single thread on the first socket S0. Using-C 0argument we toldikwid-perfctrto pin the thread with CPU core id 0. The-moption uses markers inside the microbenchmark kernel to precisely measure metrics. The-g FLOPS_DPselects the hardware counters group related to double-precision floating-point operations. - (1) shows the output of
likwid-benchthat we have seen in section8. Understand structure and output of likwid-bench. Note that we have shown only a few metrics that we want to cross-check with performance counters. - (2) onwards is the output of
likwid-perfctr. Notice the tagRegion bench. This indicates that the next output is for the source code section annotated using Marker API. There is a predefined code section namedbenchinside LIKWID microbenchmarks. - (3) shows the runtime of benchmarking kernel and how many times it was executed.
- (4) shows counters for the number of instructions executed and CPU clock counters. Note that the instructions count from
likwid-benchandINSTR_RETIRED_ANYare pretty close.likwid-benchshows static counts from benchmark written in assembly whereaslikwid-perfctrshows actually measured counters. - (5) shows individual hardware counters measured for
FLOPS_DPgroup. As we have executedAVX-512benchmark, we only see the high count forFP_ARITH_INST_RETIRED_512B_PACKED_DOUBLE. - (6) shows various derived metrics calculated for a selected performance group.
- (7) shows runtime using RDTS instruction, CPU Clock, and Cycles Per Instruction (CPI) metric. (
Runtime unhaltedmeasures only time where the CPU is in unhalted state) - (8) shows double-precision flops performance and contribution from AVX instructions. As expected, all floating-point operations are coming from
AVX-512. - (9) shows packed and scalar uops counts which represent vector and non-vector uops executed.
- (10) shows how well code is using vector instructions for floating-point operations. It's calculated as `100 * vector floating-point instructions/total floating-point instructions.
What do we expect if we run a non-vectorized peakflops microbenchmark? Let's run peakflops microbenchmark and look at important metrics. Note that we are also launching two threads to demonstrate how metrics from multiple threads is shown by likwid-perfctr:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
$ likwid-perfctr -C 0,1 -m -g FLOPS_DP likwid-bench -t peakflops -w S0:32KB:2 ... +-------------------+------------+------------+ | Region Info | HWThread 0 | HWThread 1 | +-------------------+------------+------------+ (1) | RDTSC Runtime [s] | 1.684089 | 1.684086 | | call count | 1 | 1 | +-------------------+------------+------------+ +------------------------------------------+---------+-------------+-------------+ | Event | Counter | HWThread 0 | HWThread 1 | +------------------------------------------+---------+-------------+-------------+ | INSTR_RETIRED_ANY | FIXC0 | 10497840000 | 10497830000 | | CPU_CLK_UNHALTED_CORE | FIXC1 | 4199940000 | 4199768000 | | CPU_CLK_UNHALTED_REF | FIXC2 | 4200002000 | 4199831000 | | FP_ARITH_INST_RETIRED_128B_PACKED_DOUBLE | PMC0 | 0 | 0 | | FP_ARITH_INST_RETIRED_SCALAR_DOUBLE | PMC1 | 8388608000 | 8388608000 | (2) | FP_ARITH_INST_RETIRED_256B_PACKED_DOUBLE | PMC2 | 0 | 0 | | FP_ARITH_INST_RETIRED_512B_PACKED_DOUBLE | PMC3 | 0 | 0 | +------------------------------------------+---------+-------------+-------------+ +-----------------------------------------------+---------+-------------+-------------+-------------+-------------+ | Event | Counter | Sum | Min | Max | Avg | (3) +-----------------------------------------------+---------+-------------+-------------+-------------+-------------+ | INSTR_RETIRED_ANY STAT | FIXC0 | 20995670000 | 10497830000 | 10497840000 | 10497835000 | | CPU_CLK_UNHALTED_CORE STAT | FIXC1 | 8399708000 | 4199768000 | 4199940000 | 4199854000 | | CPU_CLK_UNHALTED_REF STAT | FIXC2 | 8399833000 | 4199831000 | 4200002000 | 4199916500 | | FP_ARITH_INST_RETIRED_128B_PACKED_DOUBLE STAT | PMC0 | 0 | 0 | 0 | 0 | | FP_ARITH_INST_RETIRED_SCALAR_DOUBLE STAT | PMC1 | 16777216000 | 8388608000 | 8388608000 | 8388608000 | | FP_ARITH_INST_RETIRED_256B_PACKED_DOUBLE STAT | PMC2 | 0 | 0 | 0 | 0 | | FP_ARITH_INST_RETIRED_512B_PACKED_DOUBLE STAT | PMC3 | 0 | 0 | 0 | 0 | +-----------------------------------------------+---------+-------------+-------------+-------------+-------------+ +----------------------+------------+------------+ | Metric | HWThread 0 | HWThread 1 | +----------------------+------------+------------+ | Runtime (RDTSC) [s] | 1.6841 | 1.6841 | | Runtime unhalted [s] | 1.6800 | 1.6799 | | Clock [MHz] | 2499.9533 | 2499.9527 | | CPI | 0.4001 | 0.4001 | | DP [MFLOP/s] | 4981.0954 | 4981.1043 | | AVX DP [MFLOP/s] | 0 | 0 | (4) | AVX512 DP [MFLOP/s] | 0 | 0 | | Packed [MUOPS/s] | 0 | 0 | | Scalar [MUOPS/s] | 4981.0954 | 4981.1043 | | Vectorization ratio | 0 | 0 | (5) +----------------------+------------+------------+ +---------------------------+-----------+-----------+-----------+-----------+ | Metric | Sum | Min | Max | Avg | (6) +---------------------------+-----------+-----------+-----------+-----------+ | Runtime (RDTSC) [s] STAT | 3.3682 | 1.6841 | 1.6841 | 1.6841 | | Runtime unhalted [s] STAT | 3.3599 | 1.6799 | 1.6800 | 1.6799 | | Clock [MHz] STAT | 4999.9060 | 2499.9527 | 2499.9533 | 2499.9530 | | CPI STAT | 0.8002 | 0.4001 | 0.4001 | 0.4001 | | DP [MFLOP/s] STAT | 9962.1997 | 4981.0954 | 4981.1043 | 4981.0999 | | AVX DP [MFLOP/s] STAT | 0 | 0 | 0 | 0 | | AVX512 DP [MFLOP/s] STAT | 0 | 0 | 0 | 0 | | Packed [MUOPS/s] STAT | 0 | 0 | 0 | 0 | | Scalar [MUOPS/s] STAT | 9962.1997 | 4981.0954 | 4981.1043 | 4981.0999 | | Vectorization ratio STAT | 0 | 0 | 0 | 0 | +---------------------------+-----------+-----------+-----------+-----------+ |
For a scalar / non-vectorized benchmark, we should be able to interpret most of the above results. Here are some additional comments:
- (1) shows timing information. Note that there are now two columns
HWThread 0andHWThread 1. As we are running two threads, we will see two columns for all metrics. - As we are running the non-vector benchmark, (2) shows that all floating-point operations are now coming from scalar instructions.
- (3) is a new table showing
Sum,Min,MaxandAvgof metrics across all threads. This is useful to compare computations across all threads and find any imbalance. - (4) shows 0 value for AVX or AVX-512 flops. This is expected because
peakflopsuses non-vector instructions. This is also reflected in vectorization ratio and packed (vector) uOps which are 0 (5). - similar to (3), this shows
Sum,Min,MaxandAvgof derived metrics across all threads.
If we select L3 performance group to look at the data flowing through the L3 cache then we see:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
$ likwid-perfctr -C 0 -m -g L3 likwid-bench -t peakflops -w S0:32KB:1 ... +-------------------------------+--------------+ | Metric | HWThread 0 | +-------------------------------+--------------+ | Runtime (RDTSC) [s] | 1.6965 | | Runtime unhalted [s] | 1.6808 | | Clock [MHz] | 2499.9741 | | CPI | 0.4005 | | L3 load bandwidth [MBytes/s] | 0.0264 | | L3 load data volume [GBytes] | 4.486400e-05 | | L3 evict bandwidth [MBytes/s] | 0.0132 | | L3 evict data volume [GBytes] | 2.233600e-05 | | L3 bandwidth [MBytes/s] | 0.0396 | | L3 data volume [GBytes] | 0.0001 | +-------------------------------+--------------+ |
We will not go into individual metrics in detail but as we are using a dataset of size 32 KB, we don't see much activity at the L3 cache. If we use a higher dataset size then we should see the traffic flowing through L3:
|
1 2 3 4 5 |
$ likwid-perfctr -C 0 -m -g L3 likwid-bench -t peakflops -w S0:2GB:1 | grep " L3" | L3 bandwidth [MBytes/s] | 4875.9499 | | L3 data volume [GBytes] | 39.9531 | |
Finding and minimizing cache misses is important for application performance. We can detect L3 cache misses using L3CACHE performance groups. In the below example, we can see that as we increased the dataset size from 2MB to 1GB, the L3 miss ratio jumps from 0.0001 to 0.9561:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# run with 2 MB dataset size $ likwid-perfctr -C 0 -m -g L3CACHE likwid-bench -t peakflops -w S0:2MB:1 | grep " L3" | L3 request rate | 2.383964e-06 | | L3 miss rate | 3.083510e-10 | | L3 miss ratio | 0.0001 | # run with 1 GB dataset size $ likwid-perfctr -C 0 -m -g L3CACHE likwid-bench -t peakflops -w S0:1GB:1 | grep " L3" | L3 request rate | 9.102043e-08 | | L3 miss rate | 8.702092e-08 | | L3 miss ratio | 0.9561 | |
This section gave a very brief introduction of likwid-perfctr and how hardware performance counters can be measured. The hardware performance analysis area is quite complex and this blog post is nowhere sufficient. See the Additional Resources section for additional references.
17. But... How can I apply all of this to my own application and analyze it using LIKWID?
Throughout this blog post, we used likwid-bench to run microbenchmarks and measure various metrics. One might wonder how all of this is relevant for our own applications. How can we analyze applications instead of likwid-bench? To answer this question, let's look at a simple multi-threaded C++ application to understand what steps are involved to run it via LIKWID. We are going to use LIKWID Marker API to annotate interesting part of the application. Note that the code has some dummy, unnecessary computations just for the sake of demonstrating LIKWID features:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
#include <iostream> #include <vector> #include <sched.h> // header for likwid marker API #include "likwid.h" int main(int argc, char* argv[]) { if (argc < 3) { std::cout << "Arguments expected : number_elements scale_factor" << std::endl; return 1; } // length of arrays int number_elements = std::stoi(argv[1]); // scale factor int scale = std::stoi(argv[2]); // first, initialize marker in the serial region LIKWID_MARKER_INIT; #pragma omp parallel { std::vector<double> source(number_elements); std::vector<double> dest(number_elements); // see where thread is running, output might be mixed from multiple threads int cpu_id = sched_getcpu(); printf("Running on cpu core %d\n", cpu_id); // initialize source array for (int i = 0; i < number_elements; i++) { source[i] = i; } // each thread should call thread init LIKWID_MARKER_THREADINIT; // start of interesting code region LIKWID_MARKER_START("compute-kernel"); // dummy kernel with some floating point operation for (int i = 0; i < number_elements; i++) { dest[i] = source[i] * scale; } // end of interesting code region LIKWID_MARKER_STOP("compute-kernel"); // some dummy code to avoid compiler optimization if (scale == 999) { for (int i = 0; i < number_elements; i++) { std::cout << dest[i] << " "; } std::cout << std::endl; } } // last, close marker in serial region before end of the program LIKWID_MARKER_CLOSE; return 0; } |
Most of the above code is self-explanatory with the help of interleaved comments. Here are some additional notes:
- The example takes two CLI parameters: length of the vectors and scalar value. We allocate two vectors and perform some dummy calculation
dest[i] = source[i] * scaleto have floating-point operations. - We are using
likwid.hheader to annotate various parts of the code using markers likeLIKWID_MARKER_INIT,LIKWID_MARKER_THREADINIT,LIKWID_MARKER_STARTetc. See marker API details here. - For brevity, we have made a simple code structure. To avoid any compiler optimizations, will compile code with
-O0. - It is not mandatory to use marker API. But in real-world applications, for low-level performance analysis, we want to focus on compute portion of the code and avoid sections like initialization. The marker API helps to restrict metrics measurements for the interesting part of the code.
Assuming LIKWID is installed under $HOME/install, we can compile our example as:
|
1 2 3 |
g++ -O0 -fopenmp -DLIKWID_PERFMON example.cpp -o app.exe -I$HOME/install/include -llikwid -L$HOME/install/lib |
Note that -DLIKWID_PERFMON is required to enable LIKWID markers. Also, make sure to set LIKWID library path e.g. using LD_LIBRARY_PATH:
|
1 2 3 |
export LD_LIBRARY_PATH=$HOME/install/lib:$LD_LIBRARY_PATH |
We can now run our application under LIKWID tools. Note that we will not discuss metrics in detail as they are already covered in the previous section. In case of questions, please see this.
- Run application with two threads pinned to two physical cores of the first socket. Note that the main thread is shown separately from second thread created by OpenMP runtime:
|
1 2 3 4 5 6 7 8 9 10 |
$ likwid-pin -c S0:0-1 ./app.exe 1000 2 [pthread wrapper] [pthread wrapper] MAIN -> 0 [pthread wrapper] PIN_MASK: 0->1 [pthread wrapper] SKIP MASK: 0x0 threadid 140737132623616 -> hwthread 1 - OK Running on cpu core 0 Running on cpu core 1 |
- Run application under
likwid-perfctrto measure flops performance metrics. We are pinning threads withlikwid-perfctritself. The output is trimmed for brevity:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
$ likwid-perfctr -C 0,1 -m -g FLOPS_DP ./app.exe 10000000 2 ... -------------------------------------------------------------------------------- Region compute-kernel, Group 1: FLOPS_DP +-------------------+------------+------------+ | Region Info | HWThread 0 | HWThread 1 | +-------------------+------------+------------+ | RDTSC Runtime [s] | 0.053612 | 0.049858 | | call count | 1 | 1 | +-------------------+------------+------------+ +------------------------------------------+---------+------------+------------+ | Event | Counter | HWThread 0 | HWThread 1 | +------------------------------------------+---------+------------+------------+ | INSTR_RETIRED_ANY | FIXC0 | 180006500 | 180004900 | | CPU_CLK_UNHALTED_CORE | FIXC1 | 87216910 | 85413610 | | CPU_CLK_UNHALTED_REF | FIXC2 | 87216000 | 85413400 | | FP_ARITH_INST_RETIRED_128B_PACKED_DOUBLE | PMC0 | 0 | 0 | | FP_ARITH_INST_RETIRED_SCALAR_DOUBLE | PMC1 | 10000010 | 10000010 | | FP_ARITH_INST_RETIRED_256B_PACKED_DOUBLE | PMC2 | 0 | 0 | | FP_ARITH_INST_RETIRED_512B_PACKED_DOUBLE | PMC3 | 0 | 0 | +------------------------------------------+---------+------------+------------+ ... +----------------------+------------+------------+ | Metric | HWThread 0 | HWThread 1 | +----------------------+------------+------------+ | Runtime (RDTSC) [s] | 0.0536 | 0.0499 | | Runtime unhalted [s] | 0.0349 | 0.0342 | | Clock [MHz] | 2500.0167 | 2499.9967 | | CPI | 0.4845 | 0.4745 | | DP [MFLOP/s] | 186.5264 | 200.5704 | | AVX DP [MFLOP/s] | 0 | 0 | | AVX512 DP [MFLOP/s] | 0 | 0 | | Packed [MUOPS/s] | 0 | 0 | | Scalar [MUOPS/s] | 186.5264 | 200.5704 | | Vectorization ratio | 0 | 0 | +----------------------+------------+------------+ |
- Run the application under
likwid-powermeterand measure power consumption on the first socket:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
$ likwid-powermeter -c 0 likwid-pin -c S0:0-19 ./app.exe 10000000 1 -------------------------------------------------------------------------------- CPU name: Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz CPU type: Intel Cascadelake SP processor CPU clock: 2.50 GHz -------------------------------------------------------------------------------- Running without Marker API. Activate Marker API with -m on commandline. [pthread wrapper] [pthread wrapper] MAIN -> 0 [pthread wrapper] PIN_MASK: 0->1 1->2 2->3 3->4 4->5 5->6 6->7 7->8 8->9 9->10 10->11 11->12 12->13 13->14 14->15 15->16 16->17 17->18 18->19 [pthread wrapper] SKIP MASK: 0x0 threadid 140737132623616 -> hwthread 1 - OK threadid 140736825419520 -> hwthread 2 - OK threadid 140736518215424 -> hwthread 3 - OK threadid 140736211011328 -> hwthread 4 - OK threadid 140735903807232 -> hwthread 5 - OK threadid 140735596603136 -> hwthread 6 - OK threadid 140735289399040 -> hwthread 7 - OK threadid 140734982194944 -> hwthread 8 - OK ... -------------------------------------------------------------------------------- Runtime: 1.76107 s Measure for socket 0 on CPU 0 Domain PKG: Energy consumed: 116.674 Joules Power consumed: 66.2519 Watt ... Domain DRAM: Energy consumed: 28.4126 Joules Power consumed: 16.1337 Watt -------------------------------------------------------------------------------- |
And similarly, you can run a number of experiments that we have discussed throughout this blog post. With the examples provided in previous sections, you should be able to interpret what's going on.
Additional Resources
This blog post merely introduces LIKWID tool suite and this is just a beginning. If you want to develop a good understanding of low-level performance optimization there is a lot to learn. Here are some additional resources if you want to dive deep:
- This first LIKWID publication from 2010, LIKWID: A lightweight performance-oriented tool suite for x86 multicore environments, gives a good overview. You can find the manuscript draft also on arxiv.org here.
- This manuscript from 2012, likwid-bench: An Extensible Microbenchmarking Platform for x86 Multicore Compute Nodes, summarises likwid-bench framework well.
- The primary documentation of the LIKWID is on the GitHub Project Wiki.
- Node-Level Performance Engineering is a popular three days course by G. Hager / J. Eitzinger / G. Wellein. You can find recent events and various resources on this page (e.g. see HLRS 2020).
- If you are curious about the video course, here are the recordings of the course held at CSCS, Switzerland. This is quite old (from 2013) but the material is still relevant today.
- Georg Hager's blog is a great resource for various topics around LIKWID and performance engineering.
- Various publications from the same group are very helpful to understand low-level details. See this manuscript about Cascade Lake Processors which is relevant to this blog post.
- For quesitons, you can create GitHub issue. There is also likwid-users google group and new chat rooms on matrix.org (see information here).
Credit
All thanks to the excellent team of LIKWID developers: Jan Eitzinger, Thomas Gruber, Georg Hager, Gerhard Wellein and other team members. Special kudos to Thomas Gruber, aka TomTheBead, for driving all recent development and supporting the user community via GitHub/Google Group/Matrix.org.